The Abstraction and Reasoning Corpus made into a web game.
The aim of this project is to create an easy-to-use interface for François Chollet’s Abstraction and Reasoning Corpus (ARC-AGI), designed so that children as young as three years old can play with it. This tool explores the potential of using ARC as educational material for developing abstraction and reasoning skills in young kids, challenging cognitive abilities such as pattern recognition, logical reasoning, and problem-solving.
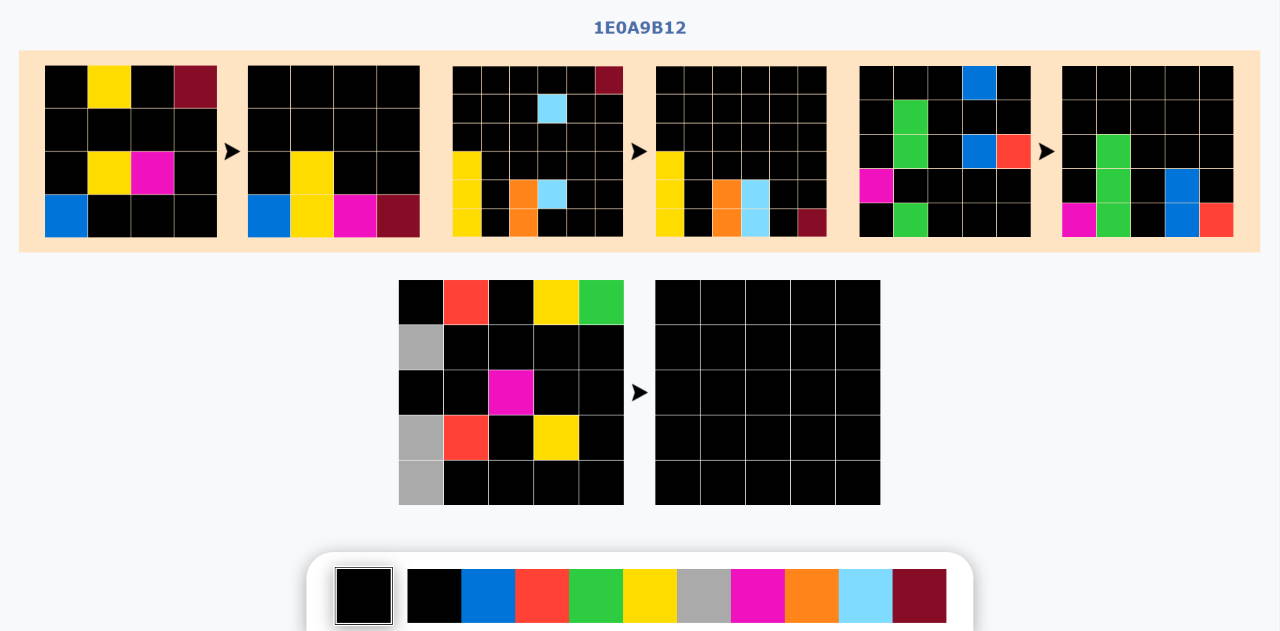
The game presents visual tasks consisting of grid pairs that represent a transformation (input → output). The player must deduce the transformation rule from the examples and apply it to a test grid.
- Child-Friendly Interface: Simplified controls allow for painting, dragging to fill, and copying grids, making it accessible for early childhood development.
- Fixed Grid Sizes: Unlike the original ARC where output size is part of the solution, here the output grid size is pre-set to reduce complexity and focus on the transformation logic.
- Printable Version: Tasks can be automatically formatted and printed on paper with adjusted colors (e.g., swapping black for white) for offline solving with markers or pencils.
Status: Not Maintained.
Cited in Scientific Literature
- Abstraction and Reasoning Challenge
- Reasoning Abilities of Large Language Models: In-Depth Analysis on the Abstraction and Reasoning Corpus
- System 2 Reasoning for Human-AI Alignment: Generality and Adaptivity via ARC-AG
- Addressing and Visualizing Misalignments in Human Task-Solving Trajectories
- Knowledge Graph and Symbolic Approaches for the ARC-AGI-2 Benchmark: Architecture, Performance, and Implications