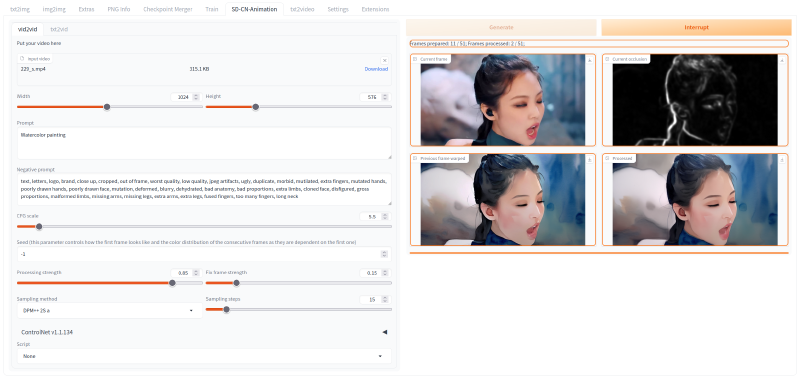
This project was developed as an extension for the Automatic1111 web UI to automate video stylization and enable text-to-video generation using Stable Diffusion 1.5 backbones. At the time of development, generated videos often suffered from severe flickering and temporal inconsistency. This framework addressed those issues by integrating the RAFT optical flow estimation algorithm. By calculating the motion flow between frames, the system could warp the previously generated frame to match the motion of the next one, creating a stable base for the diffusion model. This process, combined with occlusion masks, ensured that only new parts of the scene were generated while maintaining the consistency of existing objects.
The tool supported both video-to-video stylization and experimental text-to-video generation. In video-to-video mode, users could apply ControlNet to guide the structure of the output, allowing for stable transformations like turning a real-life video into a watercolor painting or digital art while preserving the original motion. The text-to-video mode employed a custom “FloweR” method to hallucinate optical flow from static noise, attempting to generate continuous motion from text prompts alone.
Development on this project was eventually discontinued as the field rapidly advanced. The emergence of modern, end-to-end text-to-video models provided much more coherent and faithful results than could be achieved by hacking image-based diffusion models, rendering this approach largely obsolete for general use cases.
Status: Not Maintained