
Introduction
What if I told you that a vast amount of the computation that goes into training every new Large Language Model is completely redundant?
This isn’t just a minor inefficiency, it’s a fundamental flaw in our current approach. We are spending billions of dollars and burning gigawatts of energy for every major AI company to teach their models the same fundamental understanding of the world, over and over again.
Here is the claim I am going to justify: the hardest part of what all LLMs learn is NOT next-token prediction, but rather the arbitrary data compression into a meaningful vector representation. And here’s the catch — this representation is fundamentally the same for every model (up to symmetries and precision).
The work that inspires this claim is the Platonic Representation Hypothesis. This hypothesis suggests that for any given data, there exists a “perfect” or ideal mathematical representation — a Platonic form, if you will. All our current models are simply trying to find their own noisy, imperfect approximation of this one true representation.
How a “Perfect” LLM Should Look
If the Platonic Representation Hypothesis holds true, it means we’re building our models upside down. We train monolithic, end-to-end models that learn to embed data and reason about it at the same time. Instead, we should separate these concerns.
The future of efficient AI should be built on a simple, two-part architecture:
- The Universal Encoder: A single, global, state-of-the-art model that does only one thing: convert any piece of data (text, images, sound, etc., in a continuous sequence) into its perfect “Platonic” vector embedding. This model would be trained once on a colossal dataset and then frozen, serving as a foundational piece of public infrastructure.
- The Task Model: A much smaller, specialized model that takes these “perfect” embedding (that represents all the current context window that goes to the model) as an input and learns to perform a specific task. This could be next-token prediction, classification, image denoising (for diffusion models), or even complex, one-shot reasoning like question answering or code generation. All personalization, alignment, and RLHF would happen at this much cheaper, more efficient level.
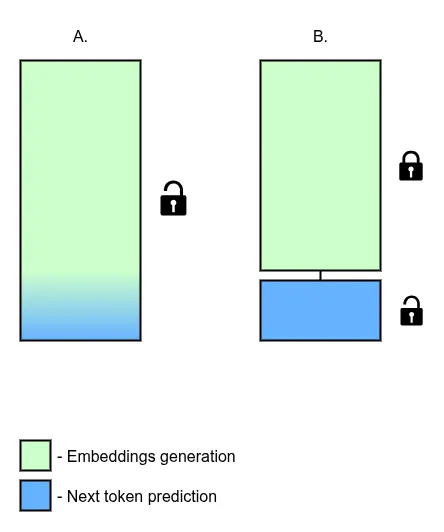
Think of it like this: today, every AI student has to first invent an entire language from scratch — its alphabet, vocabulary, and grammar — before they can even begin to learn to write an essay. In the new paradigm, they all share a common, universal language (the Universal Embeddings) with all the world’s concepts already encoded within it. The students (the Task Models) can then focus immediately on the creative act of writing the essay. Training these task-specific models would be orders of magnitude cheaper and faster.
Universal, Relational Embedding Space
So, how do we find these universal embeddings and represent them in a way that is stable and suitable for any task?
Right now, embeddings are encoded as a point in a very high-dimensional space. The problem is that the coordinate system of this space is set arbitrarily during the training process. This means every model has its own unique, incompatible space. Training the same model twice will generate two completely different spaces. You can’t just take an embedding from GPT-4 and use it in Gemini; their internal “languages” are different.
Recent research on the Universal Geometry of Embeddings shows that while the coordinate systems are different, the underlying geometric relationships between the embeddings are remarkably similar. We can remap one model’s space onto another. But this is a patch, not a solution. It proves the point: what truly matters isn’t the absolute coordinates of a concept, but its relationships to all other concepts.
What we truly care about are the distances.
Instead of a vector representing a point in space, what if an embedding vector represented a list of distances?
Imagine trying to describe the location of your city. You could give its absolute GPS coordinates (e.g., 46.10° N, 19.66° E). This is the current approach — precise, but meaningless without the entire GPS coordinate system.
Alternatively, you could describe it relationally: “It’s 180km from Budapest, 190km from Belgrade, 560km from Vienna…” This is a distance-based representation. It’s inherently meaningful.
This is how our Universal Embedding should work. Each vector would not be a coordinate, but a list of distances to a set of universal, canonical “landmark concepts” in the embedding space.
embedding("cat") = [dist_to_concept_1, dist_to_concept_2, dist_to_concept_3, ...]
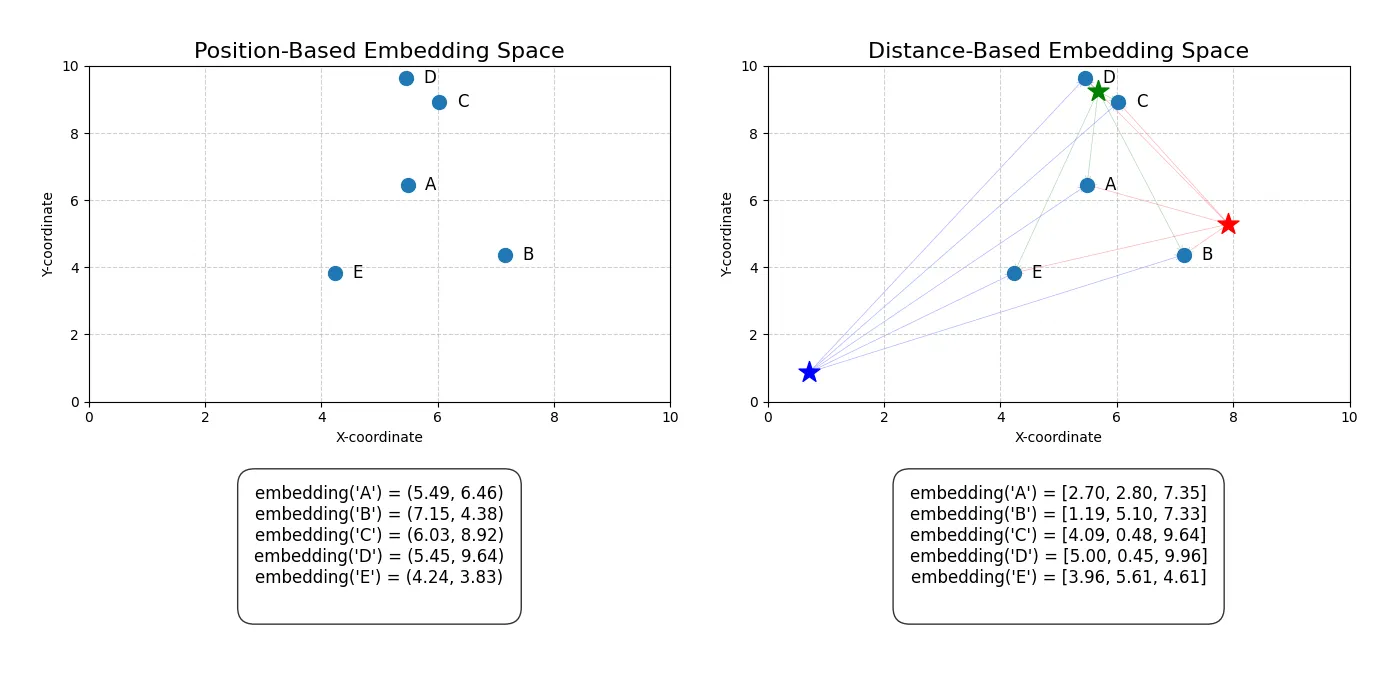
We don’t even need to know what these landmark concepts are explicitly. They can be learned by the model. The key is that they are ordered by importance, from the most general to the most specific. The first value might represent the distance to the abstract concept of “objectness,” the second to “living thing,” the tenth to “mammal,” and so on.
This structure has two incredible properties:
- It’s Stable: Because it’s based on internal distances, it’s invariant to rotation or translation. Every training run would converge to the same relational representation, creating a stable and universal standard.
- It’s Inherently Composable: This is very similar to the idea of Matryoshka Representation Learning. If you need a smaller, less precise embedding, you can just take the first N values of the vector! You’re simply using the distances to the most important landmark concepts, giving you a coarse but still highly effective representation.
We Need THE Embedding Model
The centerpiece of this vision is the Universal Encoder, or THE Embedding Model. This wouldn’t be just another model like text-embedding-3-large; it would be a foundational piece of infrastructure for the entire AI ecosystem, akin to the GPS network or the TCP/IP protocol.
This model, trained on a dataset far beyond the scale of any single company, would create this true distance-based, Matryoshka-style embedding space. This would be the definitive, canonical representation of knowledge.
The Benefits Would Be Transformative
- Backward Compatibility and Continuous Improvement: New versions of the Universal Encoder would be released as research progresses. Since each new version is just a better approximation of the same underlying Platonic representation, they should be largely backward compatible. This means you could swap in the new encoder and expect any pre-trained, task-specific models to work with the same or even better performance, with minimal re-training.
- Simplified RAG and Vector Search: Retrieval-Augmented Generation (RAG) and all vector search applications would be greatly simplified. You would only need a single base embedding model for any type of data. Your text, image, and audio databases would all exist within the same unified, coherent vector space, making cross-modal search and reasoning trivial.
- Democratization of AI: The colossal cost of training foundational models from scratch would be a one-time, collaborative effort. Researchers, startups, and even individuals could then build powerful, specialized AI applications by training only the small, inexpensive task models on top of the universal embeddings.
A Call for a New Direction
I truly believe this is the future we must build. With this approach, AI could become far more open, accessible, and environmentally sustainable.
However, this vision is a direct threat to the power held by the big companies that currently dominate the AI space. Their moat is the sheer scale of their proprietary, monolithically trained models. A shared, universal encoder is not in their immediate financial interest.
Therefore, this message is a call to action for the global ML community and AI enthusiasts. The creation of such a foundational model will likely not come from a single corporation, but from a decentralized, open-source effort. Only as a global community do we have a shot at creating an AI future that is more efficient, decentralized, and accessible for everyone.