Introduction
If you are old enough to remember the internet of the early 2000s with forums, imageboards, IRC channels and first video sharing platforms (especially early days of Youtube), you probably also remember a profound sense of freedom it gave. It was a chaotic, unpolished place where information flowed directly between people. It was a place where talented people from all around the globe could show themselves and attract an audience they could never dream of. Where ideas thrived and discussions could go ongoing for months. Today, that internet is largely gone. In its place, we have walled gardens — massive, centralized silos like Spotify, Instagram, modern YouTube, or TikTok where no real agency from the user is ever expected, the machines decides what you will see and most of the time you will like it. Today, navigating the web feels more like walking through a heavily manicured shopping mall. Every turn is engineered, every recommendation optimized for engagement, watch time, and ad revenue. People stopped sharing stuff and start living in their own echo chambers. We traded the open web for the convenience of infinite scroll and algorithmic curation.
But what exactly are all these platforms? If we strip away the slick UI and the corporate branding, a service like Spotify or YouTube is essentially just two things combined: a massive file server, and a recommendation algorithm that decides which files to stream to you next. That’s it.
The problem is that by coupling the hosting of the files with the discovery of the files, we handed over the keys to our digital culture. It enables silent shadowbanning, active censorship, algorithmic manipulation (pushing “promoted” content over what you actually want), and a total loss of privacy.
But what if we could decouple the storage of data from the discovery of data? In this article I would like to show you, that by combining old-school file sharing with modern, locally running lightweight ML models, we can completely rebuild the core functionality of these platforms without any of the dystopian side effects.
The Magic of the .meta Files
Hosting files is a solved problem. Anyone can spin up a simple HTTP or FTP server, or seed a torrent. The hard part has always been discovery. How do you find the exact song you want among millions of unindexed files scattered across the globe? How to encourage serendipity — finding the new stuff you like without having any idea of where to look at? There were no good solutions for that in the decentralized networks for many years, so they fade away. For the last decade, our answer to the discovery problem was to surrender all our personal data to centralized platforms just praying that they do have our best interest in mind.
To break the oligopoly of centralized media platforms, we don’t need a massive, blockchain-based decentralized supercomputer. Neither we need to have expensive servers. All we need is to change how we represent data.
Imagine a creator hosts a standard, simple file-sharing directory. They drop a file in there—say, a video called my_awesome_video.mp4.
Alongside this video, the server automatically generates a tiny, supplementary file: my_awesome_video.mp4.meta.
This .meta file is the secret sauce. It acts as an extremely compressed proxy for the actual media. It contains basic metadata (title, author, length) but, most importantly, it contains the objective description of this file. What it is depicting, what happening in this video, and if there is some important talking the full transcription of that video. All of that could already be produced automaticaly by modern ML models like MiniCPM-o-4_5 or OpenAI-Whisper completely locally with modest hardware requirements. Because it is just text you can change it in any way you like at any moment to make the description more accurate if the automatic description was not good enough. From that moment, this file acts like an extremely compressed version of that video, that is also readable by both humans and machines. If the original video is 2 Gigabytes, the .meta file could be just a few Kilobytes.
my_awesome_video.mp4 (2.1 GB)my_awesome_video.mp4.meta (4.2 KB)
The key is that description generation only needs to be done once per file. This leads to a beautiful separation of concerns: you can use your powerful, power-hungry desktop rig to ingest and annotate the files with local AI, and then move those files (and their .meta companions) to a cheap, low-power server (like a Raspberry Pi) to actually host them.
When setting up your server, you can configure it to automatically generate descriptions for new files as they drop into a folder, but you must weigh this against the constant GPU usage. Or maybe spend time to write those .meta files completely manually. The choice, importantly, is entirely yours.
There is also a bandwidth problem, as serving viral video to many clients through low-power server could be almost impossible. But I decided not to go into the details of this particular problem in this article. You can safely assume that eventually actual content will be hosted via BitTorrent or IPFS completely solving the bandwidth issue.
Client-Side Intelligence
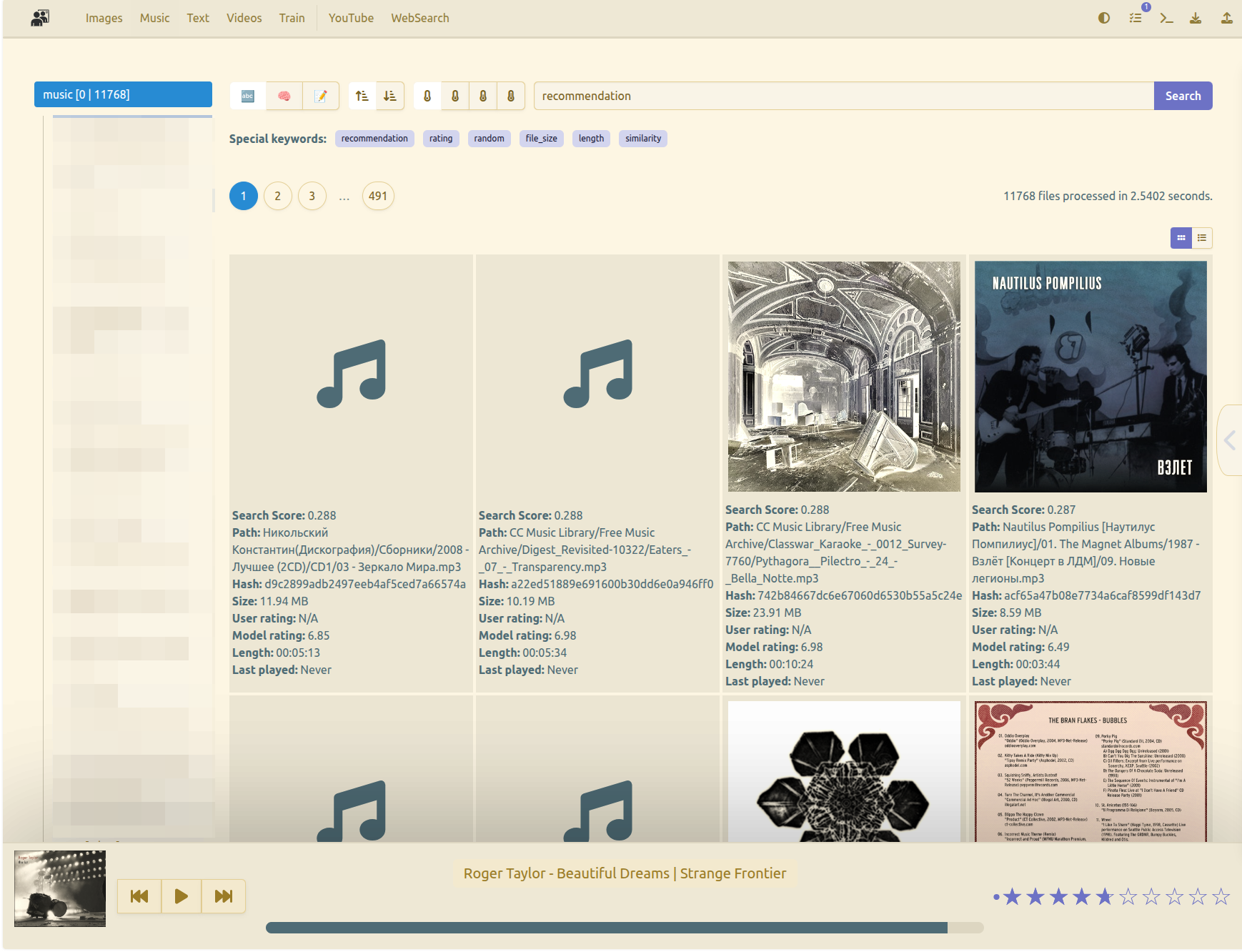
This is where your local recommendation system like Anagnorisis comes into play. When your system connects to a creator’s server, it doesn’t blindly download terabytes of video. It instantly fetches all the .meta files.
Because these text files are minuscule, your client can sweep through thousands of them in seconds. Then, it feeds these textual descriptions into your own highly personalized, locally trained recommendation model. This model evaluates the description text against your personal taste profile.
If the local model scores a .meta file highly, Anagnorisis presents it to you. Only when you click “play” does the actual 2GB media file stream from the creator’s server.
Privacy, Agency, and the End of Censorship
This leads to the most radical and liberating part of this architecture.
Because the recommendation engine runs entirely on your local machine, you never share a single byte of your personal data with an untrusted third party. There is no corporate tracking pixel, no massive redundant training runs aggregating your habits across databases. Your taste, your interests, your behaviour patterns remains your own. There is nothing to track, so nothing to abuse.
Furthermore, this obliterates the concept of platform censorship and shadowbanning. Because every creator hosts their own simple file-sharing service, they completely control the data shared through it. There is no corporate overlord to quietly suppress a video because it isn’t “advertiser-friendly.”
Conversely, all “moderation” shifts to where it belongs: the client side. If you don’t want to see certain types of content, your local recommendation model naturally filters it out based on your preferences. You build your own boundaries, rather than having an opaque algorithm dictate what is safe or appropriate for you to view. It is an honest, mathematically transparent transaction between the creator’s output and your personal taste.
The “algorithm” works for you, not for advertisers. If a creator makes something weird, controversial, or avant-garde, they are free to host it. If your local recommendation system knows you like weird, avant-garde art, it will surface it to you. There is no middleman deciding what is “brand safe.”
Local Moderation
This leads to the most radical and perhaps unsettling part for some: content moderation. By moving to a decentralized, p2p-style network, does this just become a lawless wasteland?
Not at all. The distributed nature of the network does not strip all the responsibilities from the creators/hosters. If anything, it enforces a much stricter, algorithmic, honesty. You still have to host genuinely interesting stuff, and crucially, you must describe your files faithfully in your .meta files.
If you try to game the system by writing deceptive .meta files, or if you host some form of a malicious content, users could quickly recognize the discrepancy and remove your server from their indexing list. Your server will quickly lose the reputation required to deserve to be indexed at the first place. Hosting illegal stuff on your own server might not be the brightest idea as well.
When “moderation” shifts to the client side in automated and predictable fashion, everybody could build their own boundaries.
Building It With Anagnorisis
The incredible thing is that this isn’t just an idea. Almost all of the necessary components to build this system are already implemented in the Anagnorisis project.
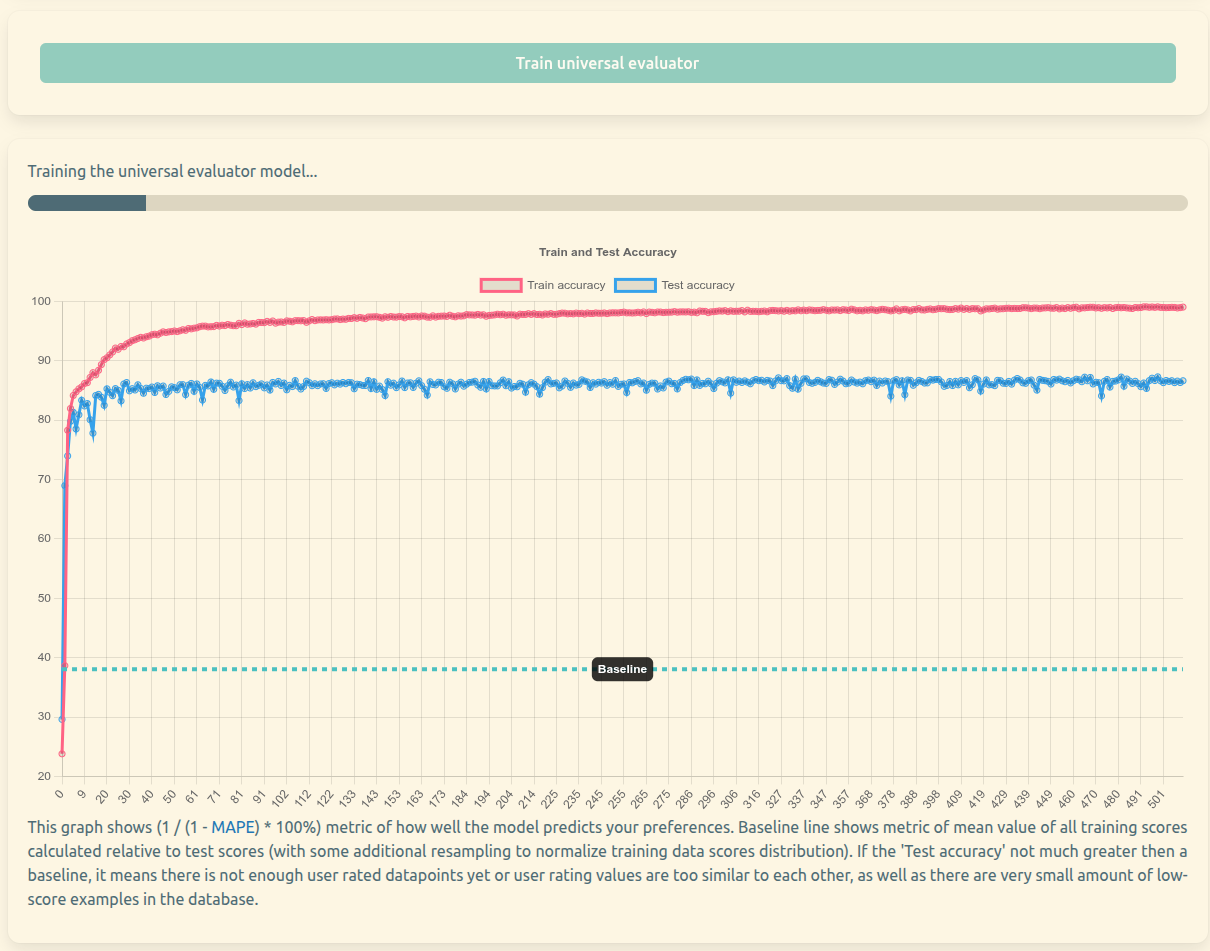
Anagnorisis is built exactly on this philosophy: keeping everything local, allowing the user to provide explicit feedback, and training a lightweight, local evaluator model that maps files descriptions to a personal interest score. There is already the logic to ingest data, embed it, and rank it locally.
I am currently building the network bridges — the simple protocols to allow Anagnorisis to fetch these .meta files from basic remote directories. Once that bridge is fully stable, anyone can become a broadcaster, and anyone can curate their own perfect, noise-free feed of the internet.
Wrapping it up
The current state of the internet is not a technological inevitability; it is merely a business model. We centralized the web because, for a long time, running complex search and recommendation algorithms required massive data centers.
But the landscape is shifting. With the rise of highly efficient, local ML models the computational moat of Big Tech is evaporating. We no longer need them to tell us what to watch, listen to, or read. By falling back on the humble, decentralized file-sharing protocols of the past that are supercharged by the local AI of today we can reclaim our agency, our privacy, and our digital culture.