
Introduction
Many years ago there was a music streaming service called Grooveshark. While being one of the first of such services it allowed things that would be unheard of today — free access to a huge music library and an option for any user to upload their own music to the website. This created quite a unique environment where you can easily find even the most obscure music you like to listen to. Furthermore there was a “radio mode” that automatically selected the music that you would like to listen, basically the same as any other today’s streaming service with one little exception — it was actually good. I was able to listen to music for hours and almost always it was the music I like that allowed me to discover many new bands that I like till this day. Unfortunately, on April 30, 2015 the site was shut down as part of a settlement of the copyright infringement lawsuits between the service and Universal Music Group, Sony Music Entertainment, and Warner Music Group.
Since then I have tried many other alternatives such as spotify, pandora, youtube music and others. None of them ever worked for me as well as Grooveshark. First of all for a long time many of them simply were not working for my country of residence, but even when they start working there was a problem — recommendations worked really badly. Mostly the recommendations were good only for the first few songs, but after that it always started to diverge into “popular” or rather “promoted” music that I don’t really like. And yes, it did not matter if it was paid or free version. The suspicion started to grow, that many services use music recommendation engines as subtle manipulation to promote some particular artists rather than satisfying my needs as a customer.
This led me into rethinking the whole idea of recommendation algorithms and how much of it is what we want to see, and how much of it is what the people in control of it want or don’t want to show.
Controlling the Algorithm. Not the other way around.
There are several different ways of how we can sort information. Some popular social media, such as Reddit heavily rely on direct human feedback for it. While this approach is clearly working it also requires a lot of moderation efforts. And because of its nature, posts on reddit get more attention when they satisfy the interest of the whole community rather than a particular person.
Another widespread approach that recommendation systems use is Collaborative filtering. It uses personal feedback from some users to predict preferences of other users. Websites such as Spotify or Youtube in its core heavily rely on this approach or at least relied in the past. The main drawback of this approach that you do need a lot of users and their personal data to make it work and even then there are no guarantee that it will always work for all users as they might have some set of interests that were not seen previously.
Finally with the rise of Machine Learning a new approach has risen — Embedding-based recommender systems. While this is an umbrella term that implies many different techniques, the general idea behind it is to use embeddings generated by some ML model directly from the data to then predict how well this data is suited for a particular user. This is the only approach that could work without a huge user base, using only a single user feedback. As such, it opens a new exciting possibility — a recommendation system that works completely locally on users’ personal devices. If implemented as an open source project such a recommendation system would be completely open to the user and controlled only by the user.
The Next Frontier
Let’s spend a minute trying to imagine how a “perfect” recommendation system might work. For a brief moment imagine that our system is totally agnostic to what kind of data it can process. No matter if it is music, videos, news or anything else. To extract embeddings of the data we will use some ML model that could take any data as an input and produce a meaningful embedding of it.
Here is some basic principle that I would like this system to satisfy:
- First of all, it should give valuable recommendations. Obviously. It should allow to sort and filter the vast amount of information.
- All the data about the user and about the user’s preferences should stay on their own personal devices and should be accessible only by the users.
- It should learn from the user’s feedback and change its recommendations alongside changing interests of the user.
We can use our ML model to generate embedding from the big pile of data, and present some of this data to the user in the form of UI interface. Like a music player, for example. Then we collect user feedback about the data and train another ML model that takes embeddings as inputs and predicts some score representing how relevant this data is for the user. We then can use this new model to suggest better recommendations, collect more data and repeat this process again and again, providing a more and more satisfying experience. And all of those steps might be performed locally, just as we wished earlier.
Here is the little diagram showing how the dataflow in such system may look like:
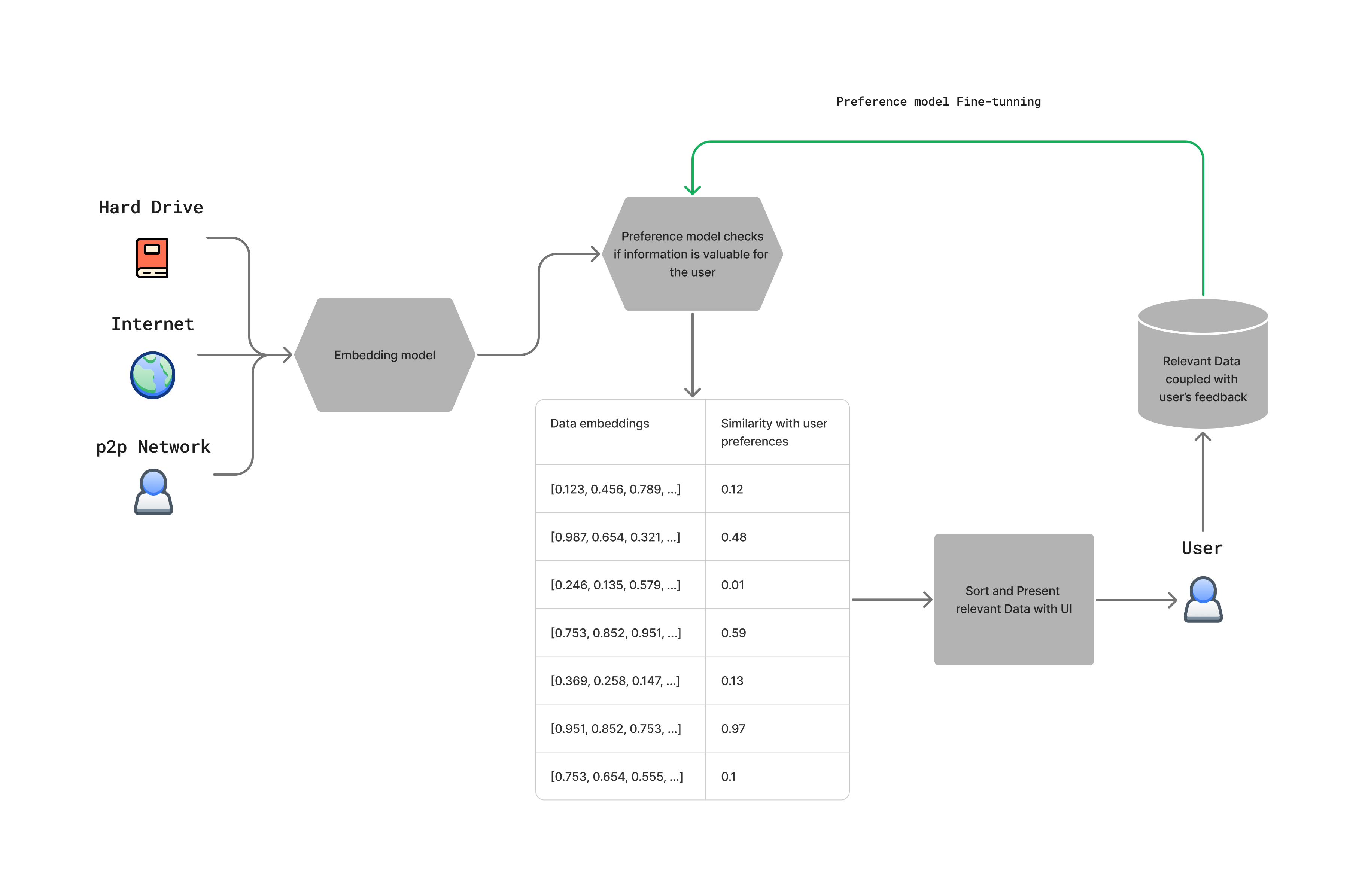
I particularly like the option of using p2p Network as a main datasource of such system. In this case we can completely move away from centralized services that control the flow of information and give users a choice to choose what kind of data they need, without any need for content moderation or sharing their personal data. To speed up calculations and not spend time and resources downloading unnecessary data, the data embeddings might be precalculated on the data provider side. So we can check if the data is valuable for us at first and only then accessing it.
To give a rating for a particular embedding we can train a model from scratch that takes embeddings as an input and predicts a value that estimates a score that a user would give to the data themselves. Right now Anagnorisis trains a separate evaluation network for each type of data, but in the future I would like to explore a more general approach, for example a multimodal transformer that could take text and embeddings as its input and produce interest scores as an output. While it would be computationally much slower than using some specialized model, it opens up new amazing possibilities that will be discussed later in this series.